바이브GeM 2는 총 2조5000개의 토큰을 사전 학습한 파라미터 140억개 모델이다. 기존 모델에서 코딩·번역·멀티턴(Multi-turn) 대화까지 추가로 지원되는 것이 특징이다. 또 이전보다 적은 메모리를 사용해 더욱 빠른 생성이 가능해졌다.
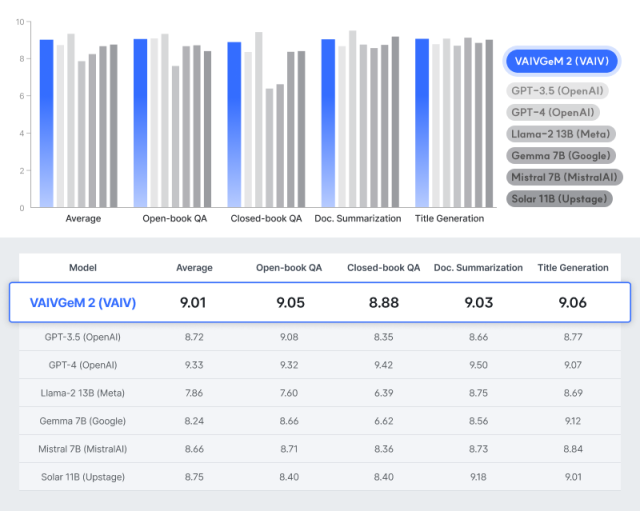
회사 측에 따르면 한국어 작업 성능 미세조정(파인튜닝) 실험 결과에서 GPT 3.5보다 높은 성능을 보이는 것으로 나타났다. 바이브는 AI 응용 시 가장 많이 활용되는 오픈북 질의응답, 클로즈드북 질의응답, 문서 요약, 제목 생성 등 4가지 주요 작업(Task)을 기준으로 테스트를 진행했다. 그 결과 메타 라마2, 구글 젬마, 업스테이지 솔라 등 기존에 오픈소스로 공개된 sLLM 중 가장 뛰어난 성능을 보였다고 밝혔다.
해당 테스트는 각 베이스 모델에 동일한 데이터를 기반으로 미세조정을 실시한 후, 각 작업별로 100개의 테스트 샘플에 대해 생성된 답변을 GPT4를 통해 평가하는 방식으로 진행됐다.
바이브GeM은 바이브가 20년 이상 축적한 자연어처리(NLP) 기술을 토대로 지난해 공개한 자체 sLLM이다. 이를 기반으로 한 다양한 AI 기반 솔루션과 서비스들을 출시하고 초거대 AI 공급사업자로도 선정돼 국민권익위원회, 조달청, 관세청, 고용노동부, 충남도청 등 많은 공공기관에 성공적인 기술검증을 진행했다.
김성언 바이브컴퍼니 대표는 "sLLM을 도입하고자 하는 기업 또는 기관들에게 바이브GeM 2는 최고의 선택이 될 것"이라며 "올해 안에 더 고도화된 바이브GeM 2.5와 바이브GeM 3을 시장에 선보이고 지속적으로 서비스와 솔루션에 반영해 나갈 것"이라고 말했다.

윤선훈 기자chakrell@ajunews.com
기자의 다른기사
©'5개국어 글로벌 경제신문' 아주경제. 무단전재·재배포 금지


![[르포] 중력 6배에 짓눌려 기절 직전…전투기 조종사 비행환경 적응훈련(영상)](https://image.ajunews.com/content/image/2024/02/29/20240229181518601151_258_161.jpg)



